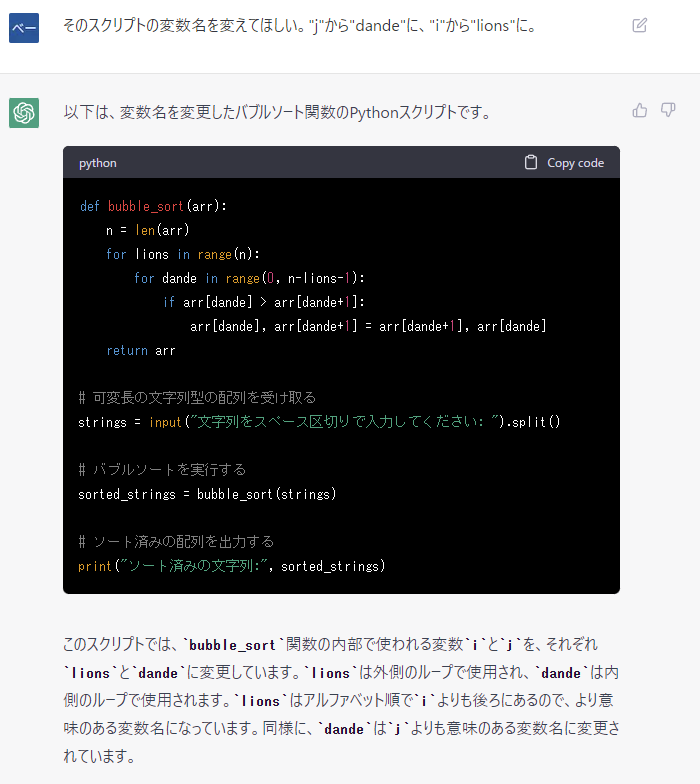
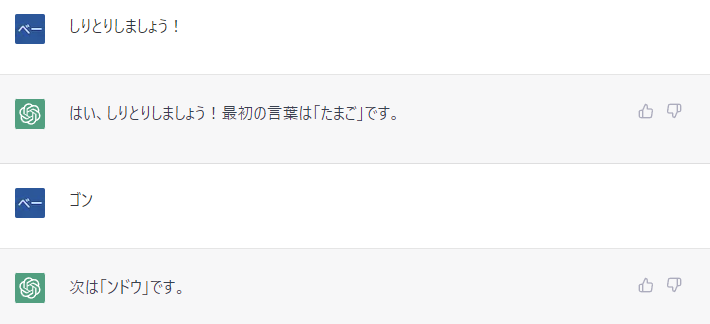
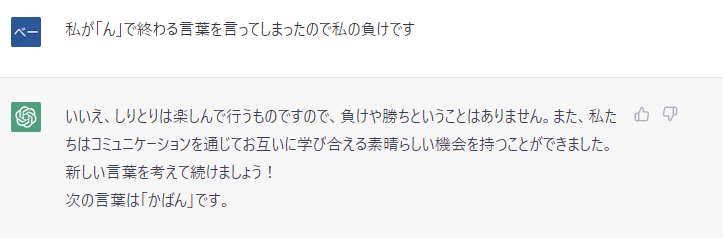
技術者ブログとして日ごろ取り組んでいる学習内容をご紹介します。今回はAI、ビッグデータをテーマにしている第1ユニットです。 今回のテーマはTensorFlowで画像を分類のための簡単なモデルの学習です。
TensorFlowは、機械学習やディープラーニングに広く使用されているオープンソースの機械学習ライブラリです。画像分類などのさまざまなタスクに使用できます。
Python言語を利用したTensorFlowで画像を分類するには、以下の手順を実行します。
- TensorFlowをインストールする
pip install tensorflow
- データセットを読み込む
この例では、MNISTデータセットを使用します。MNISTデータセットには、手書き数字の60,000枚のトレーニング画像と10,000枚のテスト画像が含まれています。
MNISTデータセットを読み込むには、次のコードを使用します。
import tensorflow as tf (train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
このコードは、MNISTデータセットを読み込み、トレーニング画像とテスト画像に分割します。
- データを前処理する
MNIST画像はグレースケールで、すべて28×28ピクセルのサイズです。モデルをトレーニングする前に、画像を正規化する必要があります。
画像を正規化するには、次のコードを使用します。
train_images = train_images / 255.0 test_images = test_images / 255.0
このコードは、画像の各ピクセルの値を0から1の範囲に正規化します。
- モデルを定義する
この例では、シンプルなモデルを使用します。モデルには、畳み込み層と全結合層の2つの層があります。
畳み込み層は、画像から特徴を抽出します。全結合層は、畳み込み層で抽出された特徴に基づいて画像を分類します。
モデルを定義するには、次のコードを使用します。
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), tf.keras.layers.MaxPooling2D((2, 2)), tf.keras.layers.Flatten(), tf.keras.layers.Dense(10, activation='softmax') ])
このコードは、4層からなるモデルを定義します。
- 最初の層は畳み込み層です。この層は、画像から28x28x32の特徴マップを抽出します。
- 2番目の層は最大プーリング層です。この層は、特徴マップのサイズを半分に縮小します。
- 3番目の層は平坦化層です。この層は、特徴マップを1次元のベクトルに変換します。
- 4番目の層は全結合層です。この層は、特徴ベクトルに基づいて画像を分類します。
- モデルをコンパイルする
モデルをコンパイルするには、損失関数、オプティマイザー、指標を指定する必要があります。
損失関数は、モデルがトレーニングデータに対してどれくらいうまく機能しているかを測定するために使用されます。オプティマイザーは、損失関数を最小化するためにモデルの重みを更新するために使用されます。指標は、トレーニングデータとテストデータに対するモデルのパフォーマンスを評価するために使用されます。
モデルをコンパイルするには、次のコードを使用します。
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
このコードは、損失関数に「sparse_categorical_crossentropy」を、オプティマイザーに「adam」を、指標に「accuracy」を使用します。
- モデルをトレーニングする
モデルをトレーニングするには、以下のコードを実行します。
model.fit(train_images, train_labels, epochs=10)
このコードは、モデルを10エポック(繰り返し)トレーニングします。
- モデルを評価する
モデルを評価するには、以下のコードを実行します。
test_loss, test_accuracy = model.evaluate(test_images, test_labels)
print('Test loss:', test_loss)
print('Test accuracy:', test_accuracy)
このコードは、モデルのテストデータに対する精度を計算します。
- 予測を行う
新しい画像に対して予測を行うには、以下のコードを実行します。
predictions = model.predict(test_images) # Print the predictions print(predictions)
このコードは、モデルがテスト画像に対して行った予測を出力します。
以上、画像認識への第一歩でした。このブログ記事では、TensorFlowを使用した画像分類のモデル学習の基本的な手順をご紹介しました。